Jedno z kluczowych wyzwań w zarządzaniu relacjami z klientami, to godzenie ze sobą perspektywy krótko i długoterminowej wartości klienta (Customer Lifetime Value, CLV). Czy lepszy jest niższy zysk tu i teraz czy potencjalnie większy, ale przecież niepewny w przyszłości? Czy i ile opłaca się zainwestować dziś w klienta by zyskać więcej w przyszłych okresach? To tylko niektóre z dylematów przed jakimi stają marketerzy. W tradycyjnym podejściu istnieje wiele „pokus” by koncentrować się na szybkich zyskach kosztem budowania trwałych relacji z klientami. Jednak w dzisiejszym niezwykle konkurencyjnym w większości branż rynku, strategiczne połączenie krótkoterminowych sukcesów z długoterminowym wzrostem wartości klienta staje się kluczowe dla przetrwania i rozwoju przedsiębiorstwa. Uczenie maszynowe w unikalny sposób może pomóc w balansowaniu tych dwóch perspektyw.
Krótko- a długoterminowa wartość klienta
Krótkoterminowa wartość klienta to metryka, która odnosi się do bezpośrednich przychodów generowanych z pojedynczej transakcji lub krótkotrwałej interakcji z klientem. Przykładami działań nastawionych na maksymalizację tej wartości mogą być krótkie kampanie promocyjne, intensywne akcje sprzedażowe, czy szybkie kampanie remarketingowe. Głównym celem jest szybki zysk – działania te często są oparte na promocjach, obniżkach cen lub ofertach typu „kup teraz”, które zachęcają do natychmiastowych zakupów.
Z kolei długoterminowa wartość klienta to całkowita wartość, jaką klient może przynieść firmie na przestrzeni lat. W tym przypadku, istotne jest nie tylko to, ile klient wyda w pojedynczej transakcji, ale także jego lojalność wobec marki, częstotliwość powrotu, rekomendacje i wpływ na innych klientów. Strategie oparte na długoterminowej wartości koncentrują się na budowaniu trwałych relacji, angażowaniu klientów i tworzeniu doświadczeń, które zwiększają ich satysfakcję oraz lojalność.
Uczenie maszynowe (ML) a maksymalizacja wartości klienta
Uczenie maszynowe (ang. machine learning, ML) rewolucjonizuje wiele aspektów funkcjonowania firm, w tym także sposób jaki zarządzają relacjami z klientami. Dzięki zaawansowanych modelom predykcyjnym, możliwe jest przewidywanie, jaka będzie wartość danego klienta w określonym przedziale czasowym. Modele te biorą pod uwagę nie tylko dane o bieżących i historycznych zakupach, ale również historię interakcji klienta z marką, poziom jego zaangażowania w kampanie marketingowe oraz wiele innych zmiennych.
Dzięki precyzyjnym predykcjom, firmy mogą różnicować swoje działania kierowane do poszczególnych segmentów – na przykład zainwestować więcej w klientów o wysokiej długoterminowej wartości lub skoncentrować się na zwiększaniu krótkoterminowej wartości klientów o mniejszym potencjale lojalności. Przykładowe podejścia do konsumentów o różnych estymacjach wartości dla firmy zestawione są w poniższej matrycy.
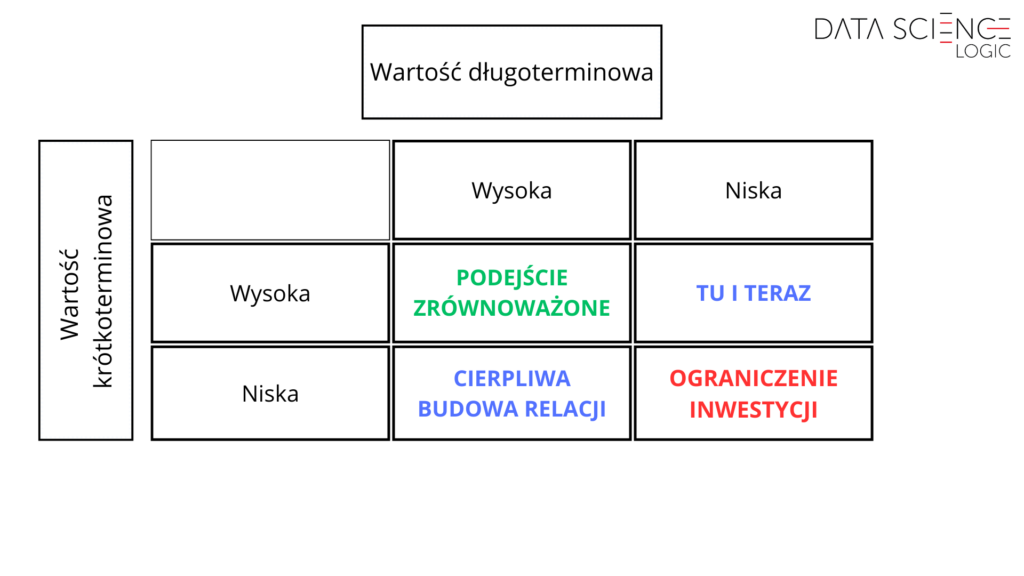
Kluczem do skutecznej implementacji takiego podejścia jest bardzo precyzyjna predykcja wartości konkretnego klienta w obu perspektywach czasowych. Osiągnięcie tego jest zaś praktycznie niemożliwe bez odwołania się do metod uczenia maszynowego, zwłaszcza w przypadku bardzo licznych baz konsumentów.
Możliwości uczenia maszynowego
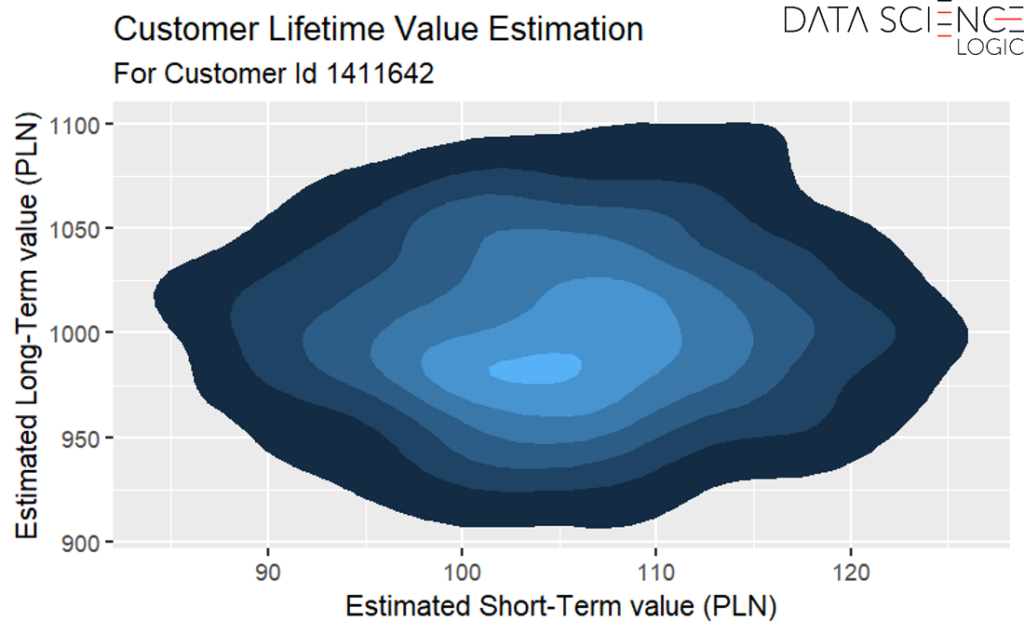
W przykładzie dzielimy horyzont wartości klienta na dwie grupy: krótki i długi. Nic nie stoi jednak na przeszkodzie by dokonać dokładniejszego podziału i stworzyć modele predykcyjne odpowiadające dowolnie dużej liczbie perspektyw czasowych relewantnych dla danej bazy konsumentów czy branży. Możliwości uczenia maszynowego nie ograniczają nas także do uproszczonych klasyfikacji typu wysoki/niski. W praktyce możemy uzyskać konkretną wartość monetarną wraz z oszacowanym marginesem błędu. Na wykresie poniżej najjaśniejszy obszar reprezentuje najbardziej prawdopodobną kombinację krótko i długookresowej wartości konkretnego konsumenta z bazy.
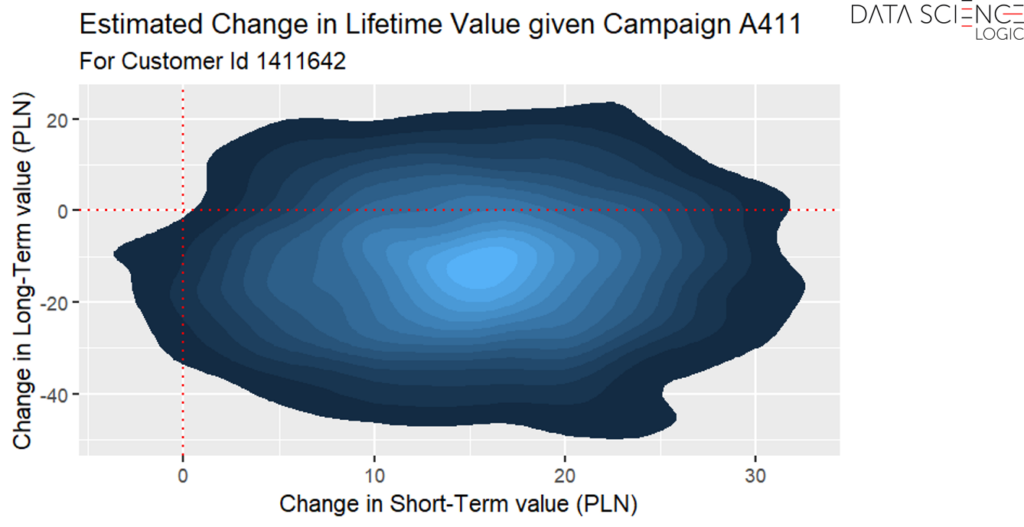
Co więcej możliwe jest również precyzyjne oszacowanie, w jaki sposób zakwalifikowanie danego klienta do konkretnej kampanii wpłynie na jego krótko- i długookresową wartość. W przykładzie poniżej kampania o kodzie A411 dla klienta o id 1411642 z dużym prawdopodobieństwem zwiększy jego krótkookresową wartość – zdecydowana większość obszaru na prawo od czerwonej pionowej linii oznaczającej 0 (brak zmiany). Model szacuje jednak, że wpływ tej kampanii na wartość klienta w długim horyzoncie będzie raczej negatywny – większa część obszaru poniżej poziomej czerwonej linii oznaczającej 0 (brak zmiany) w długim okresie.
Podsumowanie
Utrzymanie równowagi między krótkoterminową a długoterminową wartością klienta to jedno z największych wyzwań dla marketerów. Dzięki uczeniu maszynowemu, firmy mogą wreszcie połączyć te dwa cele, zamiast wybierać między szybkim zyskiem a długoterminową lojalnością klientów.
W praktyce oznacza to, że algorytmy mogą przewidywać, którzy klienci przyniosą większą wartość w długiej perspektywie, pomagając firmom inwestować w budowanie relacji z nimi, a jednocześnie optymalizować szybkie kampanie sprzedażowe dla mniej lojalnych klientów. Dzięki ML, możliwe staje się ograniczenie ryzyka „krótkowzroczności marketingowej” – firmom nie grozi już koncentrowanie się wyłącznie na szybkich, jednorazowych zyskach kosztem lojalności.
Przyszłość marketingu będzie opierała się na jeszcze bardziej zaawansowanych modelach predykcyjnych, optymalizacyjnych i automatyzacji decyzji, co pozwoli na maksymalne wykorzystanie potencjału każdego klienta – zarówno w perspektywie krótko, jak i długoterminowej.