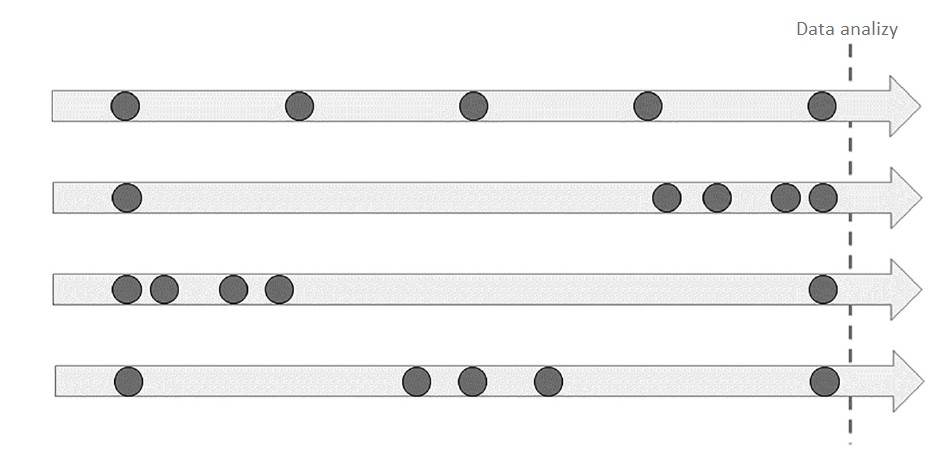
Do klientów wysyłamy nawet kilkanaście różnych wiadomości marketingowych w ciągu tygodnia. Często ta sama grupa odbiorców bierze udział w wielu różnych kampaniach. Stosujemy rozmaite kryteria kwalifikacji konsumentów do wysyłek. Zwykle różne kampanie rywalizują o tych samych „najlepszych” klientów. Nie zawsze możemy zastosować grupy kontrolne. Czasem przez pomyłkę grupa kontrolna zostaje skomunikowana. Na koniec zadajemy sobie pytanie: które z tych działań przyniosła rzeczywisty pozytywny efekt i przełożyło się na istotne dla nas wskaźniki. Czy nie brzmi to jak codzienności w wielu firmach?
Tradycyjne podejścia, jak testy A/B lub proste modele statystyczne, zawodzą w bardziej złożonych sytuacjach, w których kampanie się pokrywają, występują efekty zmiennych zakłócających, a zachowania klientów są zróżnicowane. Bayesian causal inference, czyli bayesowska analiza przyczynowa, oferuje innowacyjną i elastyczną alternatywę, która odpowiada na te wyzwania. Poniżej przyjrzymy się, jak ten model działa, jakie są jego kluczowe zalety oraz jakie ograniczenia należy uwzględnić.
Wyzwania stojące przed marketerami
Proste metody mogą być skuteczne tylko w idealnych laboratoryjnych warunkach. Rzeczywistość, w jakiej funkcjonuje rynek jest jednak od nich daleka. Marketing staje przed wieloma wyzwaniami, które utrudniają precyzyjną ocenę skuteczności kampanii. Możemy tutaj wskazać m.in.:
- Nakładanie się kampanii – klienci często otrzymują kilka komunikatów marketingowych w krótkim czasie, co utrudnia przypisanie sprzedaży do konkretnej kampanii.
- Kryteria przydzielania klientów do kampanii – wybór klientów do kampanii nie jest przypadkowy; klienci o wyższej wartości mogą częściej otrzymywać promocje, co może zakłócać wyniki analizy.
- Różnorodność klientów – Odpowiedzi klientów na kampanie są różne w zależności od preferencji, demografii i wzorców zakupowych. Pominięcie tych różnic prowadzi do wyników, które nie oddają rzeczywistej skuteczności kampanii.
Bayesian causal inference odpowiada na te wyzwania, uwzględniając zróżnicowane zachowania klientów, nakładające się kampanie oraz wpływu selekcji klientów na wynik kampanii.
Czym jest bayesowska analiza przyczynowa?
Bayesowska analiza przyczynowa to metoda statystyczna, która pozwala ocenić rzeczywisty wpływ kampanii marketingowych na sprzedaż albo inne kluczowe dla marketera wskaźniki (np. lojalność). Osiąga się to poprzez budowę modelu opisującego wzajemny wpływ różnych czynników na generowane zachowania konsumentów. Model ten integruje wcześniejszą wiedzę marketera (np. pozyskaną z analizy poprzednich kampanii), aktualizuje ją na podstawie dostępnych danych, a następnie generuje rozkład prawdopodobieństw dla efektów kampanii i zachowań klientów.
Kluczowe składniki modelu
W modelu bayesowskim dla analizy przyczynowej kampanii marketingowych kluczowe są trzy elementy:
- Bazowa skłonność do zakupu – Niezależnie do kampanii każdy klient ma pewną naturalną skłonność do dokonania kolejnego zakupu wynikającą na przykład z jego cyklu życia, aktualnego nastawienia do marki, zasobności portfela. Odpowiednie zamodelowanie bazowego poziomu wydatków z uwzględnieniem cech demograficznych, behawioralnych i transakcyjnych uwzględnić bazowy poziom wydatków, pomaga wyizolować rzeczywisty inkrementalny wpływ kampanii.
- Wpływ kampanii – Każda uwzględniana w analizie kampania ma modelowany osobno rozkład prawdopodobieństwa wpływu na sprzedaż. Pozwala to na ocenę, o ile kampania zwiększa sprzedaż powyżej bazowego poziomu wydatków klientów.
- Struktura hierarchiczna – Aby zapewnić skalowalność i poprawić interpretowalność wyników, klienci mogą być grupowani w segmenty, na przykład według demografii albo cech behawioralnych, z których każdy ma wspólne parametry.
Zalety wykorzystania bayesowskiej analizy przyczynowej w analizach marketingowych
- Dokładność atrybucji – modelowanie oddzielnych parametrów dla wpływu kampanii i bazowych zachowań klientów pozwala na rozdzielenie nakładających się efektów kampanii i dokładniejsze przypisanie sprzedaży do poszczególnych działań.
- Odporność na nielosowy wybór do kampanii – model uwzględnia wpływ kryteriów selekcji do kampanii, co daje mu przewagę nad metodami tradycyjnymi. Przykładowo, bogatsi klienci mogą być częściej objęci pewnymi kampaniami. Bez uwzględnia ich naturalnej tendencji do wyższych wydatków model przeszacowywałby rzeczywisty efekt kampanii.
- Uwzględnienie heterogeniczności klientów – omawiana metoda bayesowska pozwala na uchwycenie różnorodności zachowań i cech klientów. Model bierze pod uwagę wypływ tych cech na bazową skłonność do zakupu oraz na skuteczność oddziaływani samej kampanii (ta sama kampania może w różny sposób oddziaływać na różne grupy klientów).
- Precyzyjne oszacowanie niepewności wyniku – metoda bayesowska zapewnia pełny rozkład prawdopodobieństw wyników, co daje lepszy wgląd w wiarygodność estymacji i buduje zaufanie do metody. Minimalizuje to ryzyko wyciągnięcia niepoprawnych wniosków z przeprowadzanej analizy.
Ograniczenia baysowskiej metody
Jak każda metoda także bayesowska analiza przyczynowa ma swoje ograniczenia i wyzwania. Należą do nich przede wszystkim:
- Wrażliwość na założenia początkowe – w przypadku ograniczonej ilości danych metoda jest dosyć wrażliwa na założenia początkowe co do przypuszczalnej skuteczności kampanii. Wraz ze wzrostem liczby dostępnych danych znaczenie tych wstępnych założeń maleje;
- Kompetencje analityczne – choć same wyniki analizy są łatwe w interpretacji i przystępne dla osób bez wiedzy specjalistycznej z dziedziny data science to przeprowadzenie analizy wymaga wysokich kompetencji statystycznych, analitycznych i programistycznych;
- Wymagania Techniczne – metoda jest dosyć złożona obliczeniowo i duże bazy konsumentów z licznymi kampaniami wymagają zaawansowanej infrastruktury obliczeniowej.
Umiejętne dostosowania modelu do dostępnych danych i mocy obliczeniowej będącej do dyspozycji może zmniejszyć ryzyka i niedogodności związane z tymi wyzwaniami. Tym istotniejsze jednak są odpowiednie kompetencje osób przeprowadzających analizy dla działu marketingu.
Podsumowanie
Bayesowska analiza przyczynowa oferuje dokładne i skalowalne podejście do oceny wpływu kampanii marketingowych na kluczowe dla marketerów wskaźniki (np. sprzedaż, lojalność). Model uwzględnia zróżnicowanie klientów, wpływ kryteriów selekcji i efekty nakładających się kampanii, co pozwala uzyskać bardziej precyzyjne wyniki niż w przypadku metod tradycyjnych. Choć istnieją ograniczenia, takie jak zależność od założeń początkowych i ograniczenia w skalowalności, metoda ta dostarcza wartościowych informacji, które wspierają podejmowanie decyzji opartych na danych. Dzięki temu zespoły marketingowe mogą lepiej alokować budżety, dostosować strategię kampanii i optymalizować komunikację z klientami, zwiększając efektywność wydatków marketingowych.