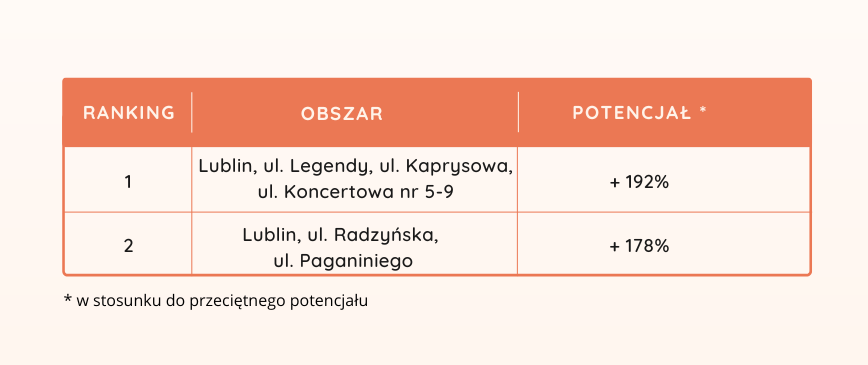
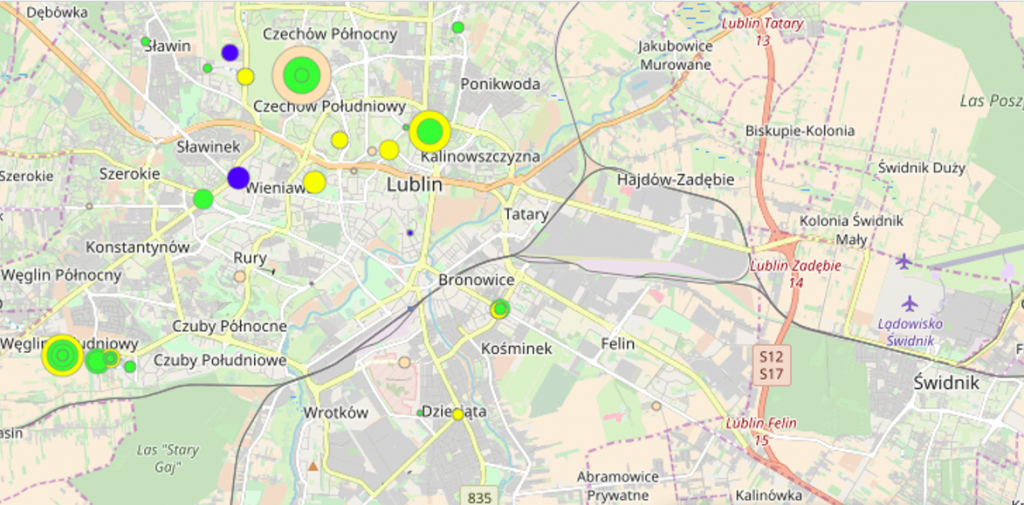
Dzisiejsi konsumenci są stale zalewani przekazami różnych marek. Wiele marek wysyła wiele komunikatów, wieloma kanałami. Powoduje to, że trudno przyciągnąć i zatrzymać na dłużej uwagę konsumenta. Jednocześnie łatwo konsumenta zmęczyć komunikacją i sprawić, że będzie na nią zwracał coraz mniejszą uwagę. Tym samym ważniejszy niż kiedykolwiek wcześniej staje się odpowiedni dobór treści, wysyłanie jak najbardziej dopasowanego do konsumenta przekazu oraz ograniczanie wiadomości, które nie są interesujące i zwiększają jedynie ryzyko uniewrażliwienia się konsumenta na przekaz.
W rozwiązaniu problemu pomaga modelowanie predykcyjne. Systemy oparte o uczenie maszynowe są w stanie z dużą dokładnością przewidzieć zainteresowanie konsumenta danym rodzajem wiadomości czy oferty. Artykuł na konkretnym i aktualnym przykładzie (z maja 2023) pokazuje, jak w praktyce zastosować wspomniane narzędzia. Ze względu na najwyższy standard zachowania poufności, liczby, które zaprezentujemy będą przeskalowane lub pokazane jako indeksy. Wiernie odwzorują jednak zaobserwowane różnice i efekty.
Problem tradycyjnego podejścia do targetowania mailingu i potrzeba zmiany
Organizacja, której dotyczy przykład, jak wiele innych, przez długie lata stosowała metodę tzw. „maksymalizacji przychodów” z bazy komunikacyjnej poprzez szerokie i częste wysyłki. Czyli w praktyce wysłano informację o ofercie do wszystkich konsumentów, którzy mieli zgodę na komunikację danym kanałem. W nielicznych wypadkach przy pomocy kryteriów eksperckich zawężano nieco komunikowaną bazę. Opierano się jednak na prostych kryteriach typu: kupił kiedykolwiek wcześniej promowany produkt, nie kupił produktu X w ciągu ostatnich 6 miesięcy, jest w kobietą w wieku powyżej 55 lat itp. Wyniki przez długi czas były bardzo dobre i nikt nie widział potrzeby zmian w stosowanym procesie. W pewnym momencie zaczęto jednak obserwować powolny spadek wskaźnika otwieralności maili (tzw. open rate). Trend spadkowy zaczął być wyraźny. W połączeniu ze zmniejszającą się liczbą nowo pozyskiwanych konsumentów, skłoniło to organizację do refleksji czy da się lepiej pracować z istniejącą bazą. Co zrobić, żeby odwrócić trend spadającego zainteresowania wysyłaną komunikacją?
Zapadła decyzja o przetestowaniu włączenia uczenia maszynowego i analityki predykcyjnej do procesu doboru konsumentów do kampanii mailingowych. Przygotowaliśmy system modelowania predykcyjnego generujący „szyte na miarę” każdej kampanii modele scoringowe. Ogólna architektura systemu przedstawiona jest na schemacie poniżej.
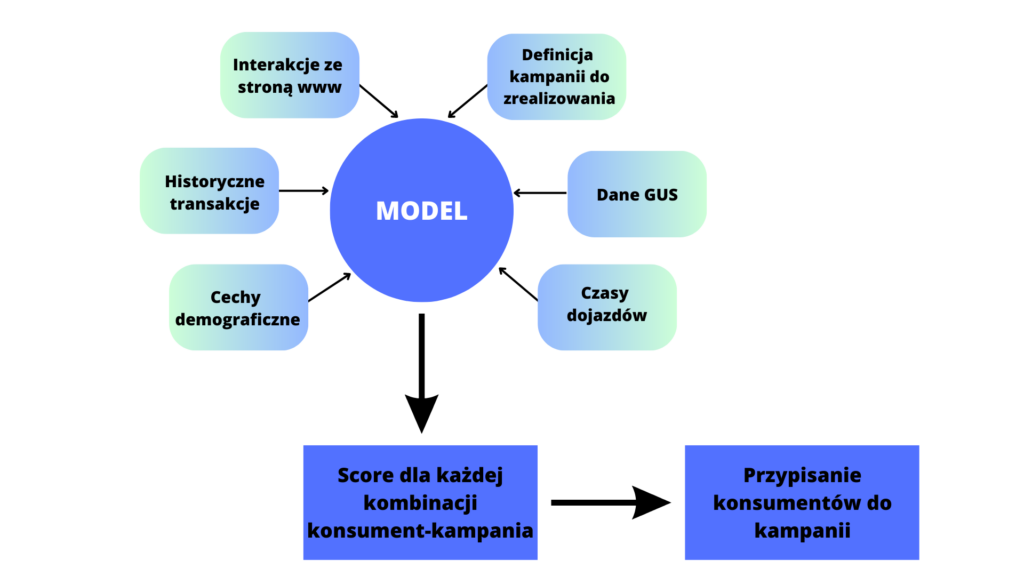
Wykorzystanie modelowania predykcyjnego w targetowaniu mailingu
Na potrzeby treningu modelu jakie dane wejściowe wykorzystanych zostało ponad 100 zmiennych z wymienionych na schemacie obszarów. Model budowane są w oparciu o zaawansowane algorytmy, będące w stanie poradzić sobie z taką mnogością atrybutów i wyekstraktować z nich jak najwięcej informacji o faktycznym profilu konsumenta. Finalnym efektem jest oszacowanie prawdopobieństwa zainteresowania daną komunikacją przez każdego konsumenta. Następnie wykorzystywane jest to do ostatecznej selekcji konsumentów do kampanii.
Wyniki zmian w procesie targetowania komunikacji spełniły (a nawet w pewnych aspektach przekroczyły) oczekiwania. Aby dowieść przydatności modelu przeprowadziliśmy eksperymenty. Połowa bazy była przedmiotem selekcji starym sposobem, druga zaś była selekcjonowana przy pomocy predykcji modelu. Trzeba przy tym zaznaczyć, że w obu grupach korzystaliśmy dokładnie z tych samych maili – ten sam temat, dokładnie taka sama kreacja. Również moment wysyłki był ten sam. Żaden z tych czynników nie mógł zatem wpłynąć na wyniki eksperymentu. Jedyną różnicą pomiędzy grupami był sposób selekcjonowania konsumentów.
Efekty zastosowania modelowania predykcyjnego
W grupie targetowanej przy pomocy modelu udało się blisko 14-krotnie ograniczyć liczebność komunikowanej grupy – na każdy 100 komunikowanych przy tradycyjnych kryteriach przypada zaledwie 7 komunikowanych według procesu opartego o model predykcyjny.
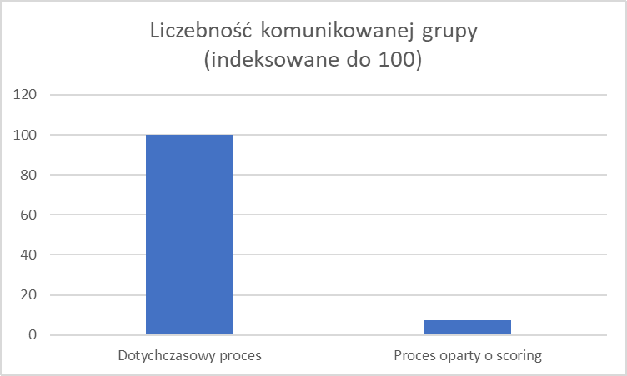
Jednocześnie tak niewielka grupa wygenerowała podobną (bo zaledwie o około 2% niższą) sprzedaż.
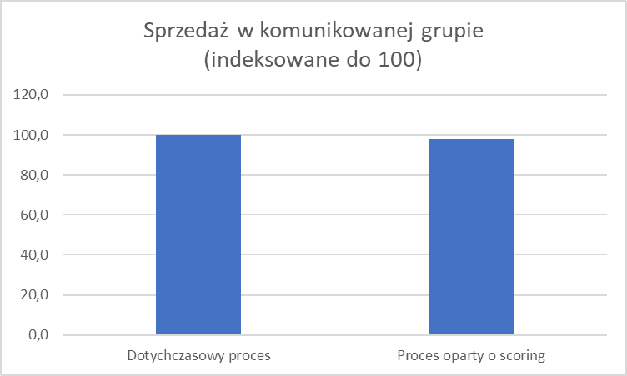
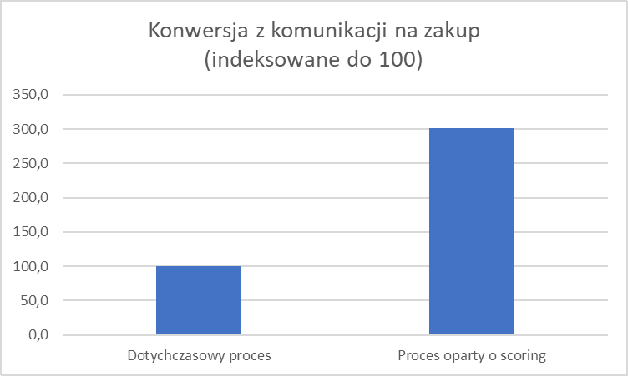
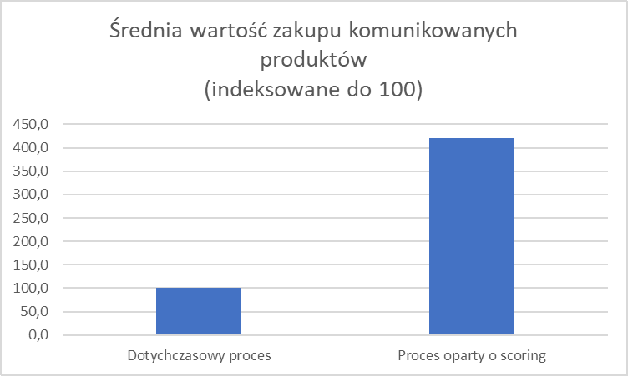
Zostało to osiągnięte dzięki znacząco wyższej (3-krotnie) konwersji w grupie przypisywanej do kampanii w nowy sposób. A także dużo (4-krotnie) większej średniej wartości paragonu w tejże grupie.
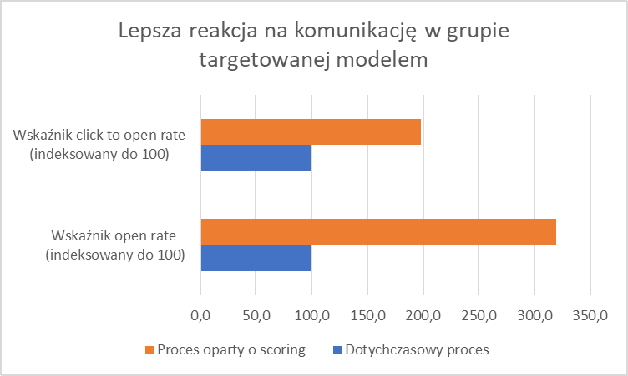
Zawężenie komunikowanej grupy pozwoliło ograniczyć ją do naprawdę zainteresowanych ofertą. Świadczy o tym dużo wyższy wskaźnik open rate (3,2 x wyższy) oraz click to open rate (prawie 2x wyższy). Wskaźnik „click to open rate” jest w tym przypadku obliczany jako CTOR = LC/LO, gdzie LC to liczba konsumentów, którzy kliknęli w linka z maila, a LO to liczba konsumentów, którzy otworzyli maila. O ile wskaźnik open rate jest w dużym stopniu zależny od tematu wiadomości, to wyższy wskaźnik CTOR świadczy o faktycznym zainteresowaniu treścią i ofertą, która zawarta jest w mailu.
Targetowanie mailingu w oparciu o model predykcyjny – podsumowanie
Dzięki zastosowaniu zaawansowanego narzędzia data science w postaci modelu predykcyjnego udało się osiągnąć:
– lepsze dopasowanie komunikacji do zainteresowań i potrzeb konsumenta
– znaczące zmniejszenie liczby komunikowanych w danej kampanii z minimalnym uszczerbkiem dla wyniku sprzedażowego (nieco ponad 2%)
– zmniejszenie „przesytu” komunikacyjnego – konsument będzie w nowym procesie otrzymywał komunikację rzadziej ale będzie ona lepiej dopasowana
Dokładny wpływ modelu i nowego procesu targetowania na trend otwieralności i klikalności mailingów, może być zbadany dopiero w dłuższym okresie i wymaga co najmniej kilku miesięcy obserwacji. Pierwsze odnotowane wyniki wyglądają jednak obiecująco i dają podstawy do oczekiwania odwrócenia wyraźnego negatywnego trendu widocznego w miesiącach przed wprowadzeniem modelu scoringowego.
Na koniec warto podkreślić, że zaletą systemu jest otwartość jego architektury na nowe źródła danych. W przypadku udostępnienia nowych zmiennych zostaną one automatycznie włączone w proces treningu modelu i wykorzystane do predykcji. Ważną cechą opisywanego rozwiązania jest także zdolność modelu do aktualizowania się w miarę napływu nowych danych w tym danych dotyczących zrealizowanych kampanii i ich skuteczności. Dzięki temu model automatycznie będzie dostosowywał się do zmieniających się potrzeb i zachowań konsumentów oraz ich reakcji na wysyłaną komunikację. Gwarantuje to użyteczność systemu także w długim horyzoncie czasowym.