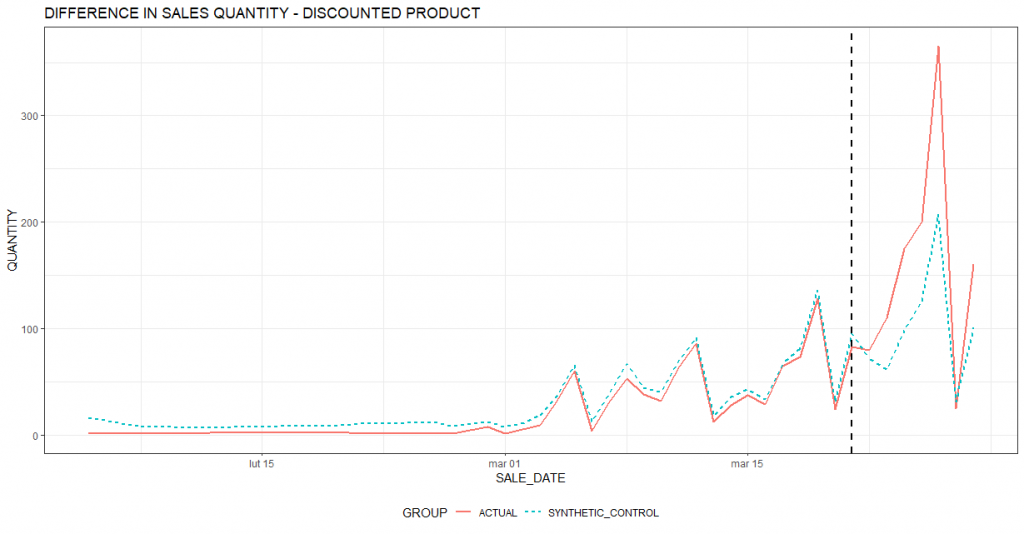
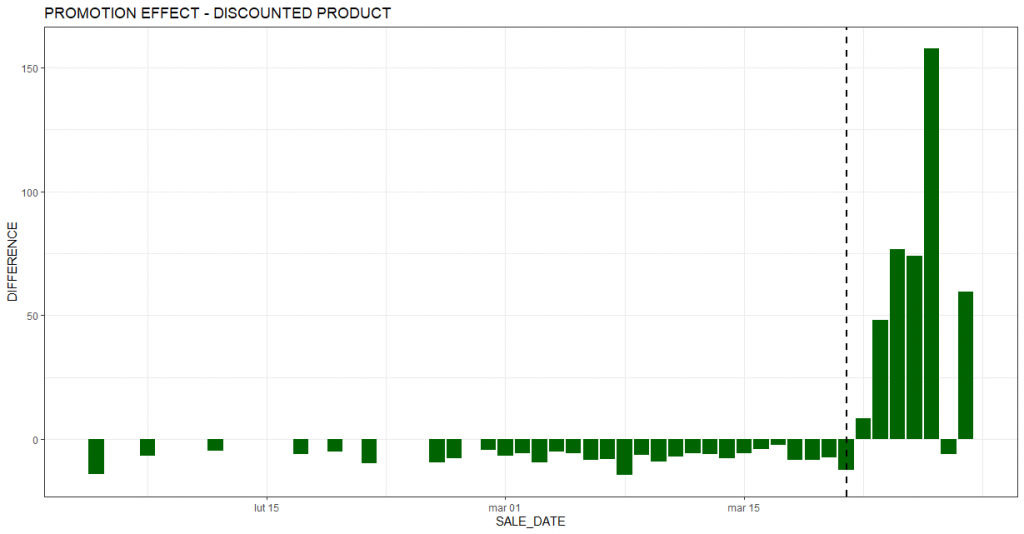
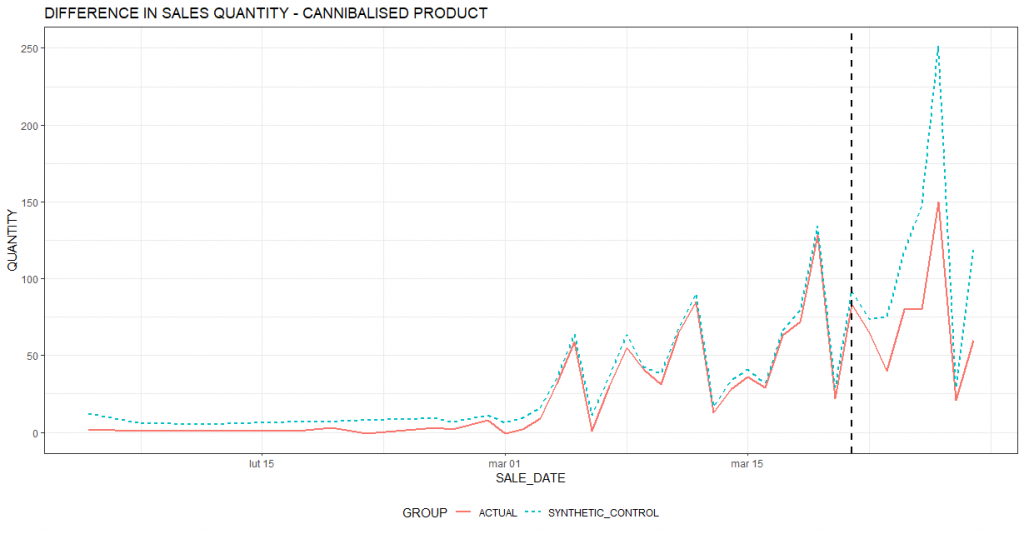
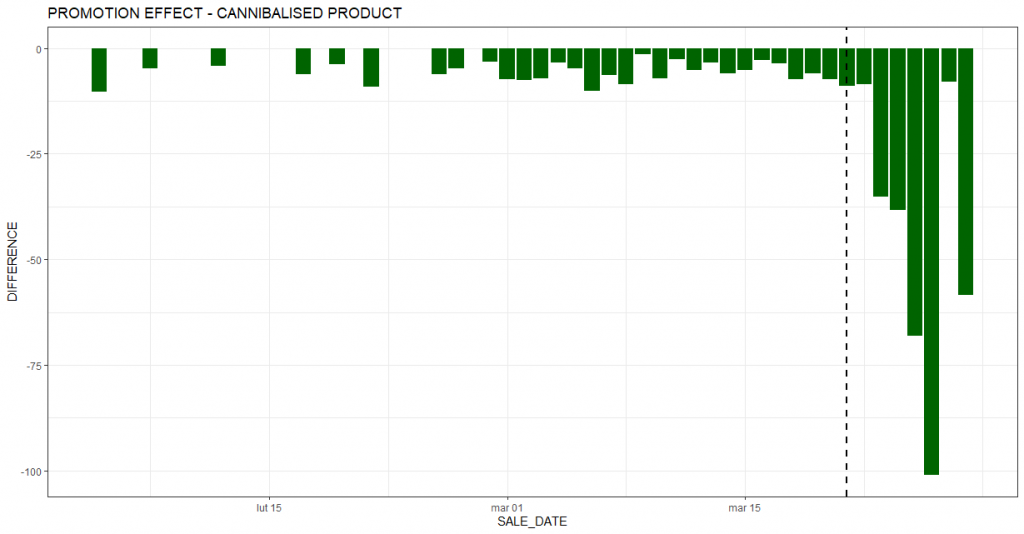
The traditional survey-based approach to measuring customer satisfaction is no longer sufficient. Using the wealth of available data, companies are already breaking through the limitations of available methods. Data-driven customer satisfaction prediction and proactive actions taken based on it are the future of this area.
Customer satisfaction is crucial to maintaining customer loyalty and is the foundation for business growth in a competitive market. Not surprisingly, this topic has long been of interest to marketing professionals. The fruits of this interest are the many methodologies for measuring customer satisfaction described in the literature and used in practice. Among the most popular are the Customer Satisfaction Score, Customer Effort Score or Net Promoter Score (NPS). A common feature of the most popular approaches is their reliance on surveys, in which the consumer is asked properly prepared questions (or even just one question). It should be noted that measuring and analyzing customer satisfaction with the help of the aforementioned surveys has proven successful in many cases. They have been and continue to be an important element in the market success of many companies. However, these methods are not without their drawbacks. According to a survey conducted by McKinsey&Company, among the most frequently mentioned by CS/CX professionals appear:
- limited range
- delay of information
- ambiguity of responses making it difficult to act on them
Limited coverage
According to the study cited earlier, a typical satisfaction survey collects responses from no more than 7% of a company’s customers. The reasons for this are multiple. Among them are budget constraints (the cost of the survey), lack of an available channel of communication with the customer or lack of consent to communication, low customer interest in answering questions. Importantly, the propensity to respond to a survey may vary depending on certain characteristics or customer experience (e.g., dissatisfied customers may respond more readily). This puts a big question mark over the representativeness of the results obtained and their generalizability to the company’s entire consumer base.
Information delay
Surveys by their very nature lag behind the phenomenon they are investigating. This makes it impossible to take pre-emptive action. We can only take action against a dissatisfied customer after he or she has completed the survey. Practitioners in the field of customer satisfaction often emphasize how big a role reaction time plays in problematic experiences. An excellent satisfaction measurement system should operate in near real time. This will make it possible to take immediate action to solve a customer’s problem or erase a bad impression formed in the customer’s mind. Ideally, it should be able to predict a customer’s growing dissatisfaction before it manifests itself in the form of a negative rating in a survey or a nerve-wracking contact with customer service. Such an opportunity does not exist in survey-only measurement systems.
Additional delays in collecting information result from the limited frequency with which questions can be asked of the consumer. Typically, surveys are conducted after a certain stage of the consumer journey, such as after a transaction. Often, there is no opportunity to ask questions at earlier steps, where issues can also arise that negatively impact the customer experience. In extreme cases, a negative experience e.g. when placing an order may end up with the transaction not happening at all. If we survey only after the transaction, in such a situation we will not get any information, because the consumer will not meet the criterion (transaction) to receive a survey.
Of course, there are companies where survey processes are not subject to such restrictions. These companies conduct surveys after every stage of the customer journey and every time the customer interacts with the company. However, it is important to remember that a survey can be perceived by the customer as an intrusive tool. Thus, an excessive number of surveys alone can negatively affect his experience. Hence, it is necessary to maintain a reasonable balance between the frequency of surveys and the consumers’ willingness to respond. In turn, it is best to think of a slightly different solution, which we will present later in the article.
The ambiguity of the answers making it difficult to take
on the basis of them
This limitation is derived from the desire to maintain a balance between the company’s information needs and consumer satisfaction. It stems from both survey coverage of individual steps in the consumer journey (described above) and limitations in survey length. Short surveys (covering one or a few questions) are not very burdensome for the consumer and may also contribute to better response. However, reducing a survey to a single question can make it difficult to understand what factors actually influenced the consumer’s evaluation of the product in this way and not in that way. If we don’t know what, in the case of that consumer, caused the negative evaluation, it is difficult to take any action based on the result to correct the bad impression.
Limiting the number of moments in which questions are asked works similarly. The rating given by the consumer (for example, “seven”) after the transaction is completed is difficult to attribute to the different stages of the consumer’s path. Determining which stages caused the consumer to deduct points from the maximum score would require asking a series of in-depth questions. This increases the time it takes to complete the survey and reduces the chance of getting an answer. On the other hand, more frequent surveying (e.g., after each step of the consumer) also raises the problems described above.
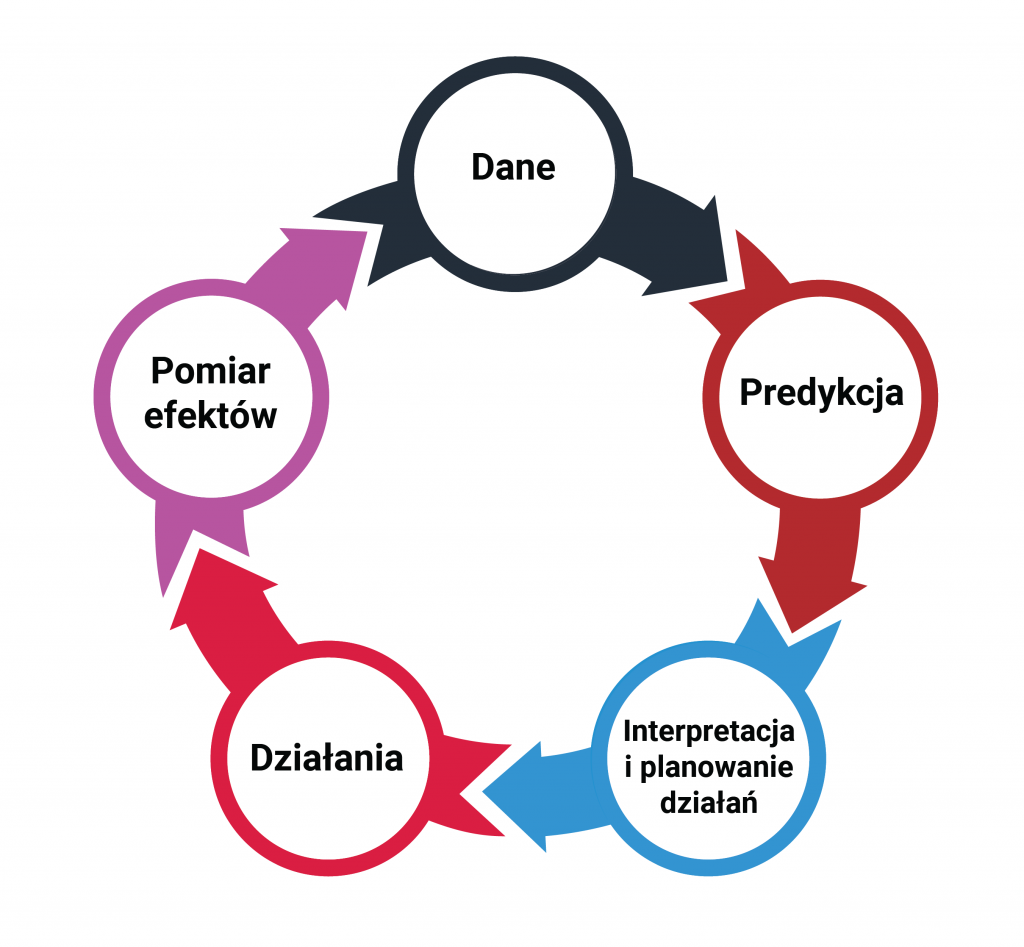
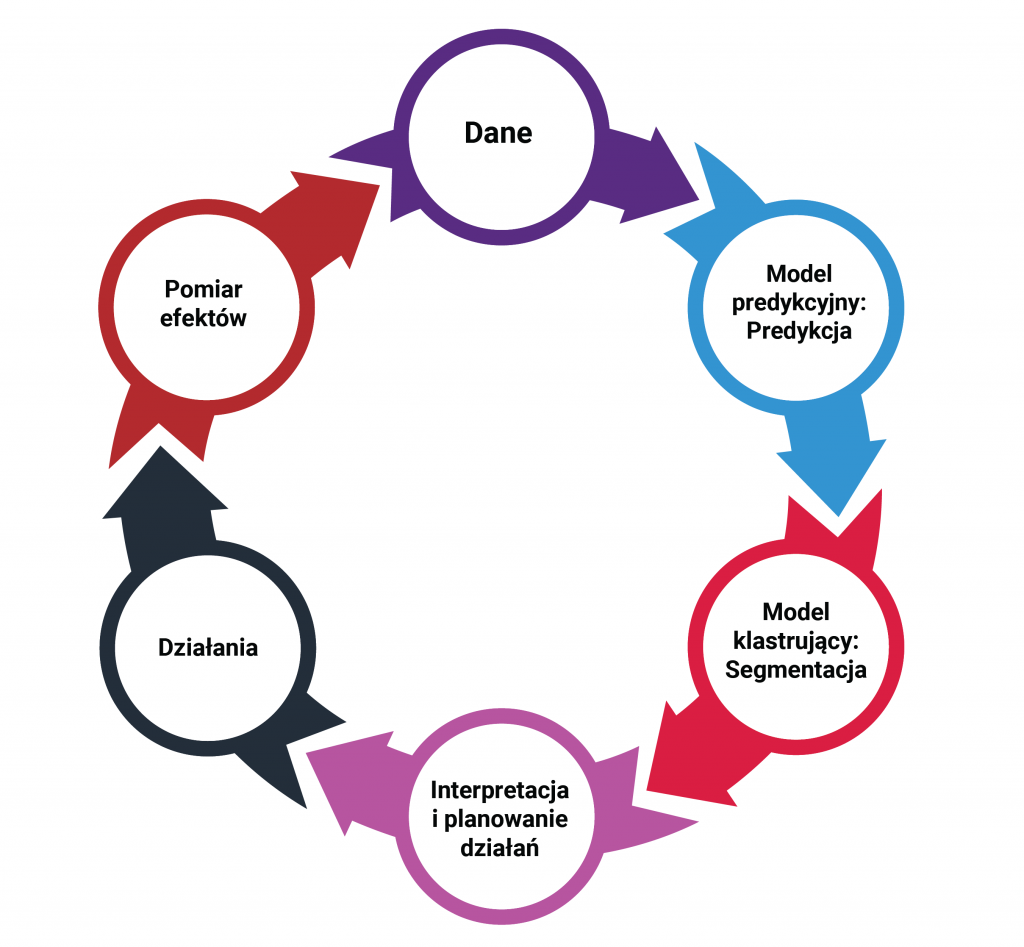
Predictive modeling as a solution
Using machine learning, it is possible to build models capable of predicting consumer satisfaction at any stage of the consumer’s journey to finalizing a transaction. This, of course, requires integrating data from many different sources usually present in a company. Mention can be made here of sales data, from a loyalty program, from a customer service desk, a hotline, a website, financial data, or, finally, data from satisfaction surveys conducted to date. This data is needed at the individual consumer level. It also requires expertise in data science – you need a team capable of building and implementing predictive models. It is worth noting that in such a solution we do not completely abandon surveys. However, they change their character. They become a typically research tool. In turn, they cease to be a tool for ongoing measurement of satisfaction.
The system works in such a way that on the basis of data collected on an ongoing basis about the consumer, it predicts his current satisfaction rate at a given moment. Moreover, it also indicates which factors positively and which negatively influence this result. This makes it possible, firstly, to identify customers against whom it is necessary to take action, and secondly, to recommend specific actions to be taken against them. The whole thing makes it possible to consistently predict customer satisfaction in near real time and take effective action.
A predictive approach to customer satisfaction is certainly the future. Companies that are the first in their market to implement this type of solution will win the battle for the customer. Even if some service “mishap” happens (and this is inevitable in large organizations) they will be able to respond to it appropriately and quickly. Thanks to an efficient system based on prediction, the reaction can be so fast that the consumer won’t even have time to think about looking for a competing supplier.