Promocja produktu, zwłaszcza związana z obniżką jego ceny, prawie zawsze kończy się wzrostem sprzedaży. Czy jednak każdy wzrost oznacza, że promocja była opłacalna? Jak często promowany produkt odbiera klientów innym substytucyjnym produktom? Jak policzyć ile wynosi rzeczywisty „inkremental” akcji?
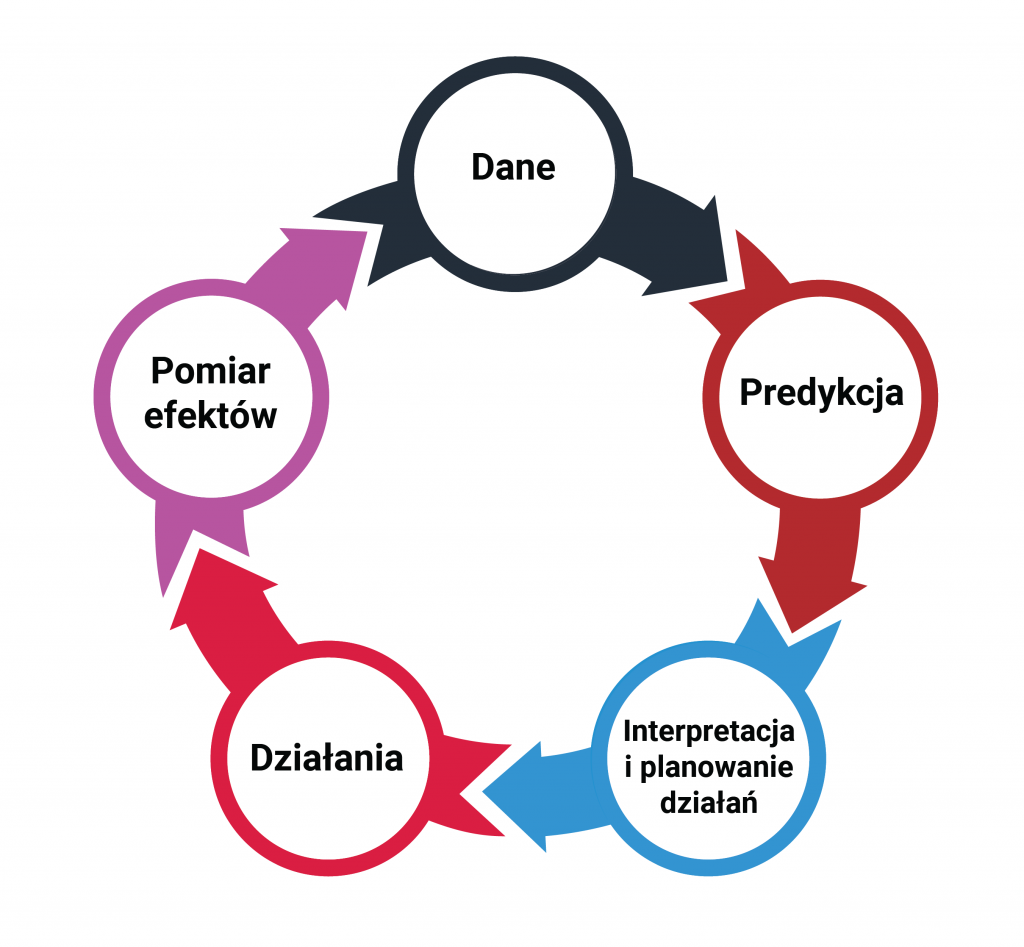
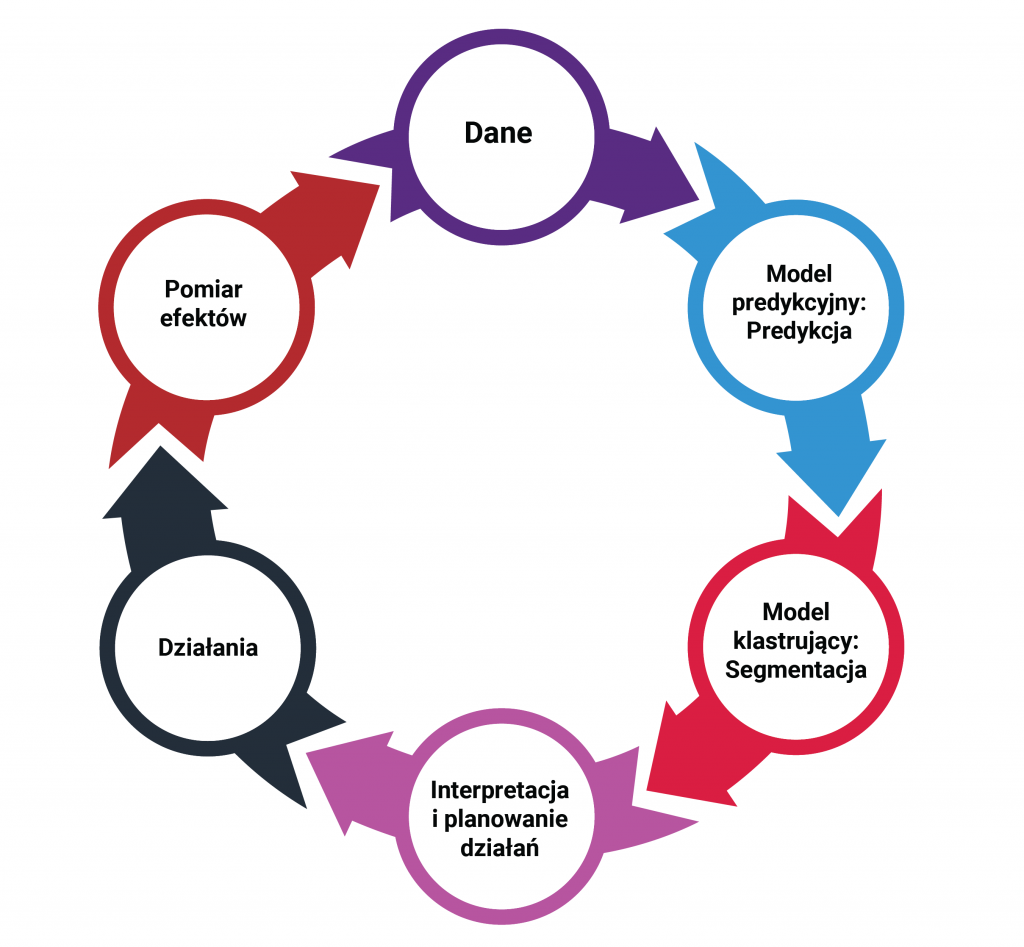
Fundamentalne pytanie do rozwiązania wskazanych we wstępie problemów brzmi: co by było, gdyby… A dokładnie: co by było, gdyby nie było promocji. Ile wyniosła by sprzedaż produktu promowanego? Ile sprzedałoby się innych produktów (zwłaszcza produktów substytucyjnych dla promowanego)? Z pozoru wydaje się to niemożliwe do ustalenia. Pytamy w końcu o alternatywną rzeczywistość, której nie jesteśmy w stanie zaobserwować. Nie można jednocześnie wprowadzić promocji i jej nie wprowadzać. Okazuje się jednak, że bazując na postępach statystyki, nauki o danych i badań nad sztuczną inteligencją z ostatnich lat, jesteśmy w stanie w naukowy, metodyczny i rygorystyczny sposób dokonać oszacowania wspomnianych efektów. Stosowana metoda opiera się o tzw. syntetyczne grupy kontrolne. Czyli mówiąc w pewnym uproszczeniu grupy porównawcze tworzone przez specjalny algorytm na podstawie dostępnych obserwacji sprzedaży produktów podobnych.
Przeanalizujemy to na przykładzie zilustrowanym na wykresie poniżej. Czerwona linia pokazuje rzeczywistą sprzedaż produktu (w sztukach). Widać, że przed marcem sprzedaży produktu była śladowa. Widoczny jest też wyraźny cykl tygodniowy ze szczytami w soboty i wyraźnymi spadkami w niedziele (związanymi z zakazem handlu i ograniczoną liczbą punktów, które mogą prowadzić sprzedaż). Można zauważyć też trend wzrostowy sprzedaży od początku marca. Czarna pionowa przerywana linia pokazuje dzień startu promocji. Cena produktu została znacząco obniżona. Widać wyraźny wzrost sprzedaży.
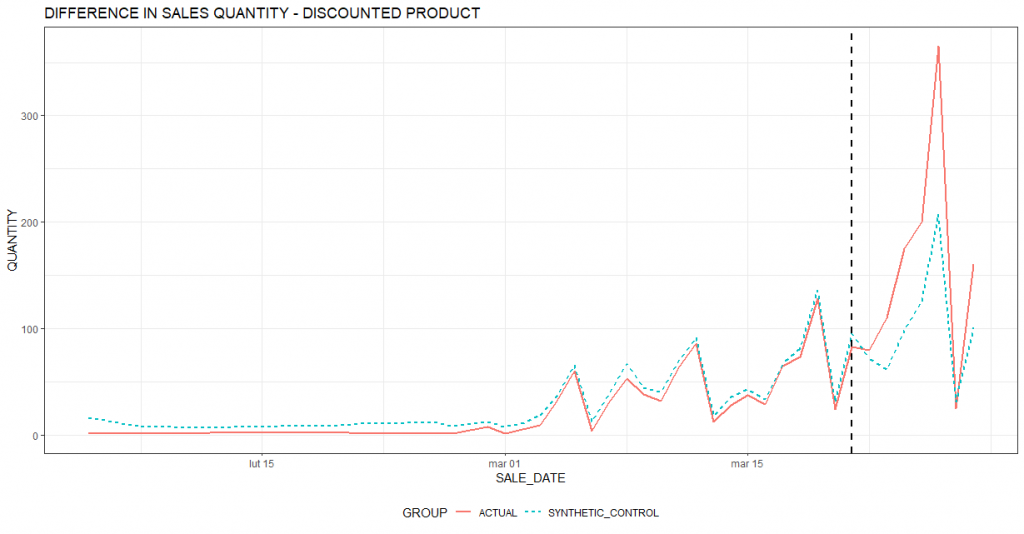
Jasnoniebieska przerywana linia to oszacowane przez algorytm zachowania się sprzedaży promowanego produktu gdyby nie było promocji (rzeczywistość alternatywna). Widać, że nawet bez promocji nastąpiłby wzrost sprzedaży (zgodnie z widocznym od początku marca trendem wzrostowym). Nie byłby on jednak aż tak duży. Można więc przyjąć wniosek, że promocja wygenerowała dodatkową sprzedaż produktu.
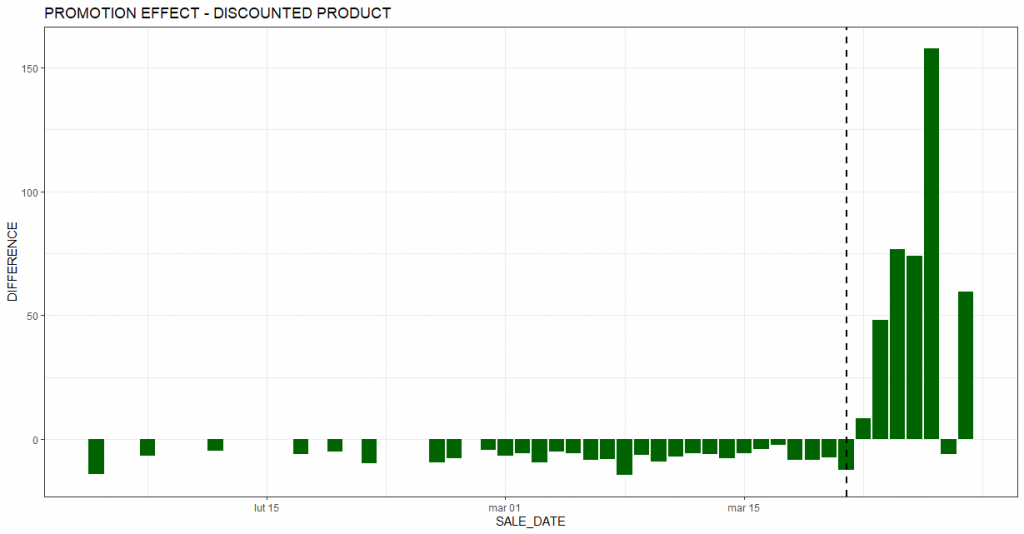
Kolejny wykres pokazuje podsumowanie inkrementalnej sprzedaży dla poszczególnych dni. Podobnie jak na wcześniejszym wykresie, czarna pionowa przerywana linia oznacza początek okresu promocji. Większość słupków jest wyraźnie wyższa od zera, co oznacza szacowany wzrost sprzedaży w stosunku do scenariusza bazowego (czyli braku promocji). Okres poprzedzający promocję na lewo od przerywanej linii, to okres kalibracyjny. Na podstawie tego okresu algorytm uczy się najlepszej kombinacji produktów stanowiących grupę porównawczą (tzw. syntetyczną grupę kontrolną). Im słupki w okresie kalibracyjnym bliższe są zeru tym lepiej dopasowana grupa porównawcza. Oczywiście w realnych przykładach (takich jak prezentowany w tym artykule) trudno znaleźć dopasowanie idealne. Stąd słupki odchylają się nieco od 0. Istotne jest jednak to, że skala tych odchyleń jest zdecydowanie mniejsza w okresie kalibracyjnym. Uprawdopodobnia to wniosek o rzeczywistym dodatnim wpływie promocji na sprzedaż.
W tym miejscu można by zamknąć analizę i pogratulować osobom odpowiedzialnym za promocję. Pojawia się jednak pytanie, na ile promocja przyciągnęła nowych klientów lub zwiększyła popyt u istniejących, a na ile jedynie przesunęła popyt z innych komplementarnych produktów, które nie były w tym okresie promowane. Innymi słowy, na ile promocja skanibalizowała sprzedaż innych produktów.
W celu odpowiedzi na to pytanie przeprowadzimy podobną analizę do zaprezentowanej powyżej. Tym razem jednak czerwona linia będzie oznaczała sprzedaż produktu substytucyjnego do produktu promowanego. Dla tego właśnie produktu chcemy oszacować efekt kanibalizacji.
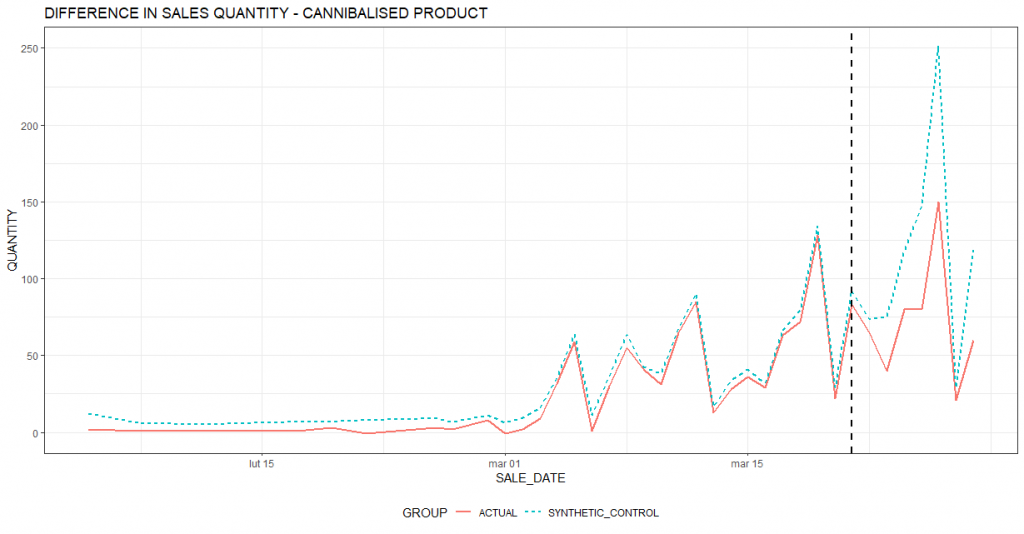
Podobnie jak wcześniej pionowa czarna przerywana linia oznacza datę początku akcji. Po rozpoczęciu promocji czerwona linia jest niżej od jasnoniebieskiej przerywanej, co oznacza, że produktu substytucyjnego sprzedaje się mniej niż sprzedałoby się go w scenariuszu bazowym zakładającym brak promocji. Warto również zwrócić uwagę, że w okresie poprzedzającym promocję (okresie kalibracyjnym) obie linie są bardzo blisko siebie, co oznacza, że algorytm poprawnie skalibrował grupę porównawczą.
Wykres poniżej podsumowuje efekt kanibalizacji w poszczególnych dniach. Widać, że w każdym dniu okresu promocji produktu sprzedało się mniej w porównaniu do rzeczywistości, w której promocja nie miała by miejsca.
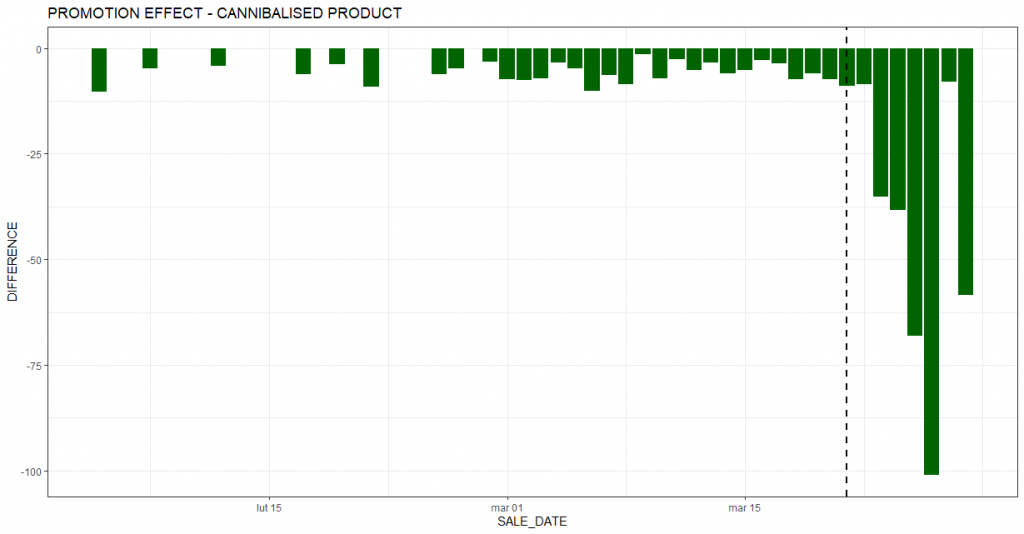
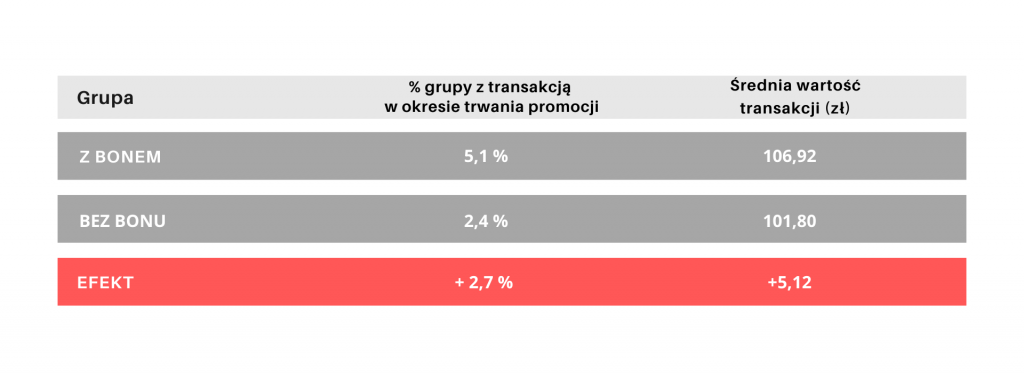
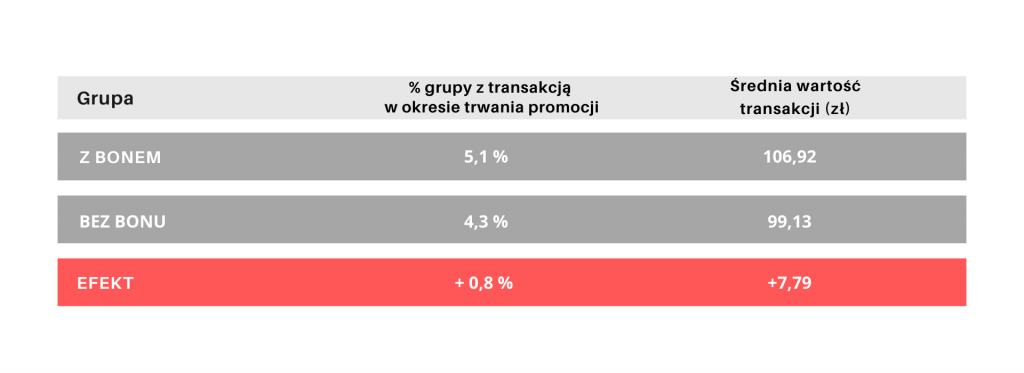
W analizowanym przypadku inkrementalna sprzedaż produktu promowanego wyniosła 407 sztuk. Oceniając akcję promocyjną, trzeba jednak uwzględnić efekt kanibalizacji. W tym przypadku utrata sprzedaży na produkcie substytucyjnym do promowanego wyniosła w okresie promocji 326 sztuk. Nie biorąc pod uwagę tego czynnika, moglibyśmy znacząco przeszacować finansowy efekt akcji i wyciągnąć nieprawidłowe wnioski, co do jej opłacalności. To zaś mogłoby się przełożyć na nieoptymalne decyzje dotyczące organizowania podobnych promocji w przyszłości.
Najlepszym sposobem pomiaru efektów jest przeprowadzenie zrandomizowanego eksperymentu. Nie zawsze jest to jednak możliwe. Trudno wyobrazić sobie, w jaki sposób w tym samym czasie i dla tej samej grupy konsumentów jednocześnie przeprowadzić promocję i jej nie przeprowadzić. W takich sytuacjach nieocenione w analizie marketingowej mogą być nowoczesne metody analityczne oparte o syntetyczne grupy kontrolne między innymi takie jak zaprezentowana w dzisiejszym artykule.