A customer base is an important asset for any business. The data collected about customers allows better targeting of communications and preparation of more tailored offers. However, a healthy business needs a steady stream of new customers. In turn, there is usually no (or little) data on them. Where to look for customers? And can data science therefore help in reaching them?
The question posed above is best answered with an example. Some time ago, one company wanted to significantly expand the customer base buying its flagship product. Experience suggested that this product appealed to a completely different group of consumers than the company’s typical customer. An advertising campaign using billboards and flyers was planned. With a limited budget, however, the company did not want to “flood” the entire city and surrounding areas in which it operates with materials. It intended to focus its efforts and budget in locations with the highest probability of high return on investment.
The first idea on how to use data to solve this problem was to see where the current customers purchasing the product were coming from. Their address data was in the database thanks to the loyalty program in place. An analysis of the demographic and behavioral profile of customers buying the flagship item – the subject of the campaign – was conducted. Compared to typical customers, this group was characterized by an overrepresentation of the 30-35 age group by more than 10 percentage points, a higher proportion of men and higher income. It was assumed that particularly attractive from the point of view of the planned campaign would be areas with an above-average share of residents with such characteristics. Therefore, areas (neighborhoods, districts, municipalities) were selected on the basis of several data sources. These came from, among other sources, information made publicly available by the Central Statistical Office and offered commercially by various private providers.
Concerned that simply identifying customer locations of higher interest would not be enough, a more precise estimate of the sales potential of individual locations was needed. In short, an answer was sought to the question: how many sales can we count on? For this purpose, a predictive model was built, which was able to indicate for each area the expected future sales in any defined period. The model used variables such as the age and gender structure of each district, income per household, travel time to the service point, and purchasing behavior of existing customers in the area, among others. The average prediction error of the model varied within +/- 6%. To illustrate the level of detail with which the model was able to pinpoint locations, the following table contains the definition of the top two recommendations of the predictive model.

The areas with the greatest potential identified by the model were also visualized on maps (example of one below).
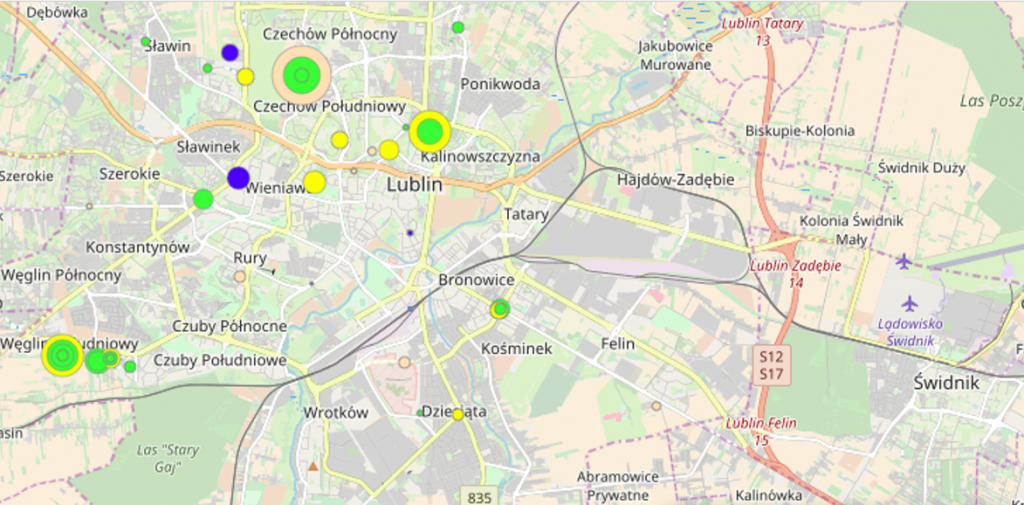
In order to assess the relevance of the model’s recommendations, the effects of the activities carried out in the group of the top 10 locations identified by the model were compared with the 10 locations from places 11-20 of the ranking. The return on investment in the group recommended by the model was more than 21% higher compared to the comparison group.
Data science in the right way, combining internal and external data sources with different levels of detail (individual customer data with aggregated data describing entire areas), can help solve various problems faced by business. Thus, it contributes to increasing return on investment.